シンボル・グラウディング問題 G検定
G検定の勉強をした中で、シンボル・グラウディング問題が興味深かった。
これは単純に、「コンピュータは記号の意味が分からないので、それを意味するものと結びつけられない」という意味だそうだ。
いつもなら、ああ、それでオートエンコーダーでは特徴量を取り出すことが概念化と結びつくっていうことと、漠然と理解して終わるところですが、受験のために覚えようとしていたのでこんな事が。
英語の勉強をしていて、「TOEIC800点の壁」と言われるものがある。
600点くらいは普通に勉強していれば取れるが、800点を突破するには、多くの英語の文章を読まなくてはいけないと言われる。
自分も、なにせブランクが空いてしまって、TOEICも悲惨な事に、、
つまるところ、G検定より前にTOEICを何とかしろという状態orz
G検定は就活に役立つかどうか分からないけれど、TOEICは役立つというか致命的になりかねない。
そして、すぐに就活が出来ない状態では、勉強して点数を回復する事が大切だろうという事で英語の勉強をした。800点の壁を突破する事を考えて、英語の小説を読んだ。
そして、気づいた事。
もしかして、「800点の壁」は、「シンボルグラウディング問題」ではないか?
私の英語の覚え方は対訳コーパス的になってしまっていたために限界があった。この方法でも、600点は突破できる。しかし、実際の英語は実は文脈的である。
しばしば、日本語は文脈の言葉と言われる。つまり、同じ「すみません」も、場面によって、「謝罪」、「声かけ」、「どけ」など、意味が異なる。英語はそうではないと思っていたが、英語もそういった使い方が多い。
とても困るのは真逆の意味が含まれる場合がある。日本語で言えば、「やばい」がそうで、「危険」なのか、「とてもいい」のか。
英語で"pending"が「棚上げ」なのか、「すぐに起こる事」なのか。使われる文脈によって異なる。
松尾先生が相手にしている東大の学生はこんな事でつまずかないのだろうけれど、私は人間でもここでつまずく。え、、pendingって、棚上げではなかったの!?
シンボル・グラウディング問題は、人間でも起こるのだ。
G検定 受験を止めた話
久しぶりに書き込みます。
このところ、シミュレーション用のPCが致命的に壊れました。セットアップしていくつかの論文のプログラムを動作可能にしていたPCでした。それが再起不能に。orz
またようやく、良い就職先の兆しが見えてきたところで、私生活のゴタゴタがとんでもないことになってしまい、就活どころではなくなってしまいました。
それですっかりブランクが空いてしまったので、再び就活をするにあたり、新しい資格でも取ろうと思い、G検定を受けてみようと思いました。
問題集を買ってある程度勉強し、申込をしました。申込期日は7月9日。
しかし、フォーマットを記入したのですが、コンビニ支払いを選択したので、レスポンスのメールが送られてこなかった。あれ、ないぞと思って数日後、妙なところにポップアップしている事に気づきましたが、しかし今度は選択肢の中にセブンイレブンがない。また、一つのコンビニを選択すると確定されてしまって他の選択をやり直せないようだった。
どうしてくれよう、、と思った。
他にも気になったこととして、以下※1の記述。
- 2021年 第2回 「G検定(ジェネラリスト検定)」 一般 (13200円)
- (※1)再受験 過去2年以内の試験を1回以上受験したことがある方を対象とします。
- (※2)修了証保有 AI For Everyone修了証を取得保有している方を対象とします。
と、いろいろ書いてある。これは何?
以前、stanfordの機械学習コースをcouseraで取ったとき、苦労して成し遂げ、お金を振り込んだにも関わらず、結局、certisfactionを得る事が出来なくて、問い合わせたら期限が切れたのでお金を再度振り込めと言われ、しかも当初より高額になっていて止めたことがあった。そんな事も思い出され。。
受験料13,200円は、TOEICなど他の検定料もたいてい6,000円程度なのと比べると高い。学生は5,500円だそうだけれど、全てこのくらいにして欲しい。
更に、過去2年以内の受験者に対して割り引き受験を実施するという仕掛けが用意されていることがなにか、いやらしいものを感じた。これまでの合格率は高かったようだが、合格率も下げてくるかも知れない。
そんなこんなで、納得できる買い物ではないと感じて、受験を取りやめた。
もしも、今勉強した程度で受かる内容であれば、その資格は就活にも役立たない気がするし、もし落ちたら、高い受験料がもったいなすぎる。
一応、勉強はしたのでそれなりに勉強にはなりました。
放置してあった松尾豊先生の本も読んだし。
実効再生産数Rt計算 エクセルで簡単EpiEstimは何を計算しているか
御無沙汰しています。
すっかり忘れてしまいそうなので以前理解した内容を書いておきます。
エクセルでも簡単に実効再生産数Rtを計算できるEpiRstimについて
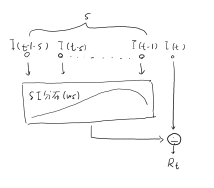
EpiEstimの動作は、Step1、Step2からなる
Step1 SIの分布(ws)を計算。
ここで、SI(Sireal Interval)は、一人目の発症からその人がうつした人が
発症するまでの期間。
Step2 Step1の結果を用いてRtを計算する。
過去の発症者の数(I(t-τ), τ=1,2,..s)にwsを畳み込み積分し(sはwsの最大長)、
I(t)をその値で割ったものがRt
とってもシンプル♪
ちなみに、ここまで紹介してきた以下の設定では、Step1は決め打ちにしています。
なので、実際に計算しているのはStep2のみです。
キーワード コロナ 新型コロナ COVID-19
【新型コロナ】実効再生産数Rtをエクセルで計算したら1ヶ月後が見えた?(WHOお墨付きEpiEstimで)(3)
一昨日、昨日に続き、WHOお墨付きEpiEstimのexl版で実効再生産数を計算しました。
実効再生産数Rtは1人目から2人目にうつした倍率である事を利用すると、1ヶ月後が見えてくるかも知れない。
さっそく、エクセルで計算だ!
全国のRtはEpiEstimで0.9だったので、もしその値がずっと変わらないと想定して計算してみると、1ヶ月後のpcrポジティブは激減する。入院治療を要する人、重篤患者数も同様に減少して、1ヶ月後をこのようにざっくり試算できる。

2020/9/27までの直近2週間ほどのデータを用いて、2020/9/24のRtを推定した。
この時のグラフはこのようになる。あくまで、1ヶ月間Rtが全く変わらない想定のグラフです。。ありえないけれども。

試しに、Rtが1以上になる沖縄のデータで同様に計算すると、1ヶ月後に感染者が倍になる事になる。


日本全国都道府県のRtを計算した結果が以下のようになる。

水色がRt<1で縮小傾向、黄色は1以上2.5未満で黄色信号、ピンクは2.5以上でR0より大きい値の県になる。といっても、元々感染者数が少ない県では少し感染者が発生しただけで大きな値になってしまうため、信頼度は疑問。でも、中国地方が目立つね。何か特別なことがあったんでしょうか?
1ヶ月後の入院治療を要する患者数をざっくり推定するとこのようになった。ピンクは病床数を上回る。黄色はかなりの割合を占めなくてはならないことになる(他の病菌お患者さんもいるので現実的には難しいと予想される。)。島根、広島、鹿児島は今の状態で感染者数が増加すると患者を収容できなくなるという事になる。

キーワード PC xls COVID-19
【新型コロナ】実効再生産数Rtをエクセルで計算してみた(WHOお墨付き!?)(2)
昨日の続きです(ただし、使用するデータを2020/02/27-09/26に更新しました)。
WHOお墨付きのEpiEstimのexl版で出力したデータをエクセル上で加工します。
(1) 新しいエクセルシートにEpiEstimのOutput2 R estimatesタブからRのmeanの計算値をコピーし、Time periodの値に気をつけて、対応する年月日を貼り付ける。
(2) こんなグラフが簡単に描ける。

(2) こんなグラフが簡単に描ける。

(3) 左右の0.05quantileと0.95quantaileも使ってあげると、もっとカッコイイ(?)

【参考文献】
WHO(2020) Public health criteria to adjust public health and social measures in the context of COVID-19
Anne Cori(2013) A New Framework and Software to Estimate Time-Varying Reproduction Numbers During Epidemics
【新型コロナ】実効再生産数Rtをエクセルで計算してみた(WHOお墨付き!?)
前回の書き込みから御無沙汰しております。
猛反省して新型コロナ(COVID-19)の論文を調べ、紆余曲折してはやウンヶ月。PythonとRのインストールにからかわれておりました。^^;
世界保健機構(WHO)報告(3月12日)から、再生産数の定義は以下
Rt (the effective number of secondary cases per infectious case in a population)
1人の感染者が2人目にうつす数。
SIは、1人目が発症してから、うつした人が発症するまでの期間。
そこにはRプログラムが添付されていて(https://CRAN.R-project.org/package=EpiEstim)
その作者Anne Coriさんの論文A New Framework and Software to Estimate Time-Varying Reproduction Numbers During Epidemicsでは、EXCELもリリースされていました。
http://tools.epidemiology.net/EpiEstim.xls
つまり、WHOお墨付き!?
この論文、2013年です。専門家の方ならとうにご存じですね。orz
と思いつつご紹介
使い方もいたってシンプル。
EpiEstim.xlsをダウンロード
↓
DataタブのIncidenceに読み込みたいデータを貼り付ける
↓
Estimate R!
↓
結果がFigureに表示される
計算内容は、この論文もさることながら本人が監修しつつ他の方が書いている論文が簡潔で分かり良いです。こちらも機会があればご紹介します。
さっそく、日本の新型コロナのRtを計算してみましょう。
(1) http://tools.epidemiology.net/EpiEstim.xlsからダウンロード
(2) コンテンツの有効化

(3) Dataタブを開くと


(4) オリジナルは他の感染症のデータになっているので、COVID19Serial Intervalの値に書き換える。ちょっと古いかも知れないがWHOで5-6日と言っていたので、mean5.5日、SD1くらいにしてみよう。

(5) 日本のデータをIncidenceに貼り付ける。このとき、データ長を変えた場合には、Timeを変更してMax Timeもそれに合わせて変更する。

厚生労働省のデータ(https://www.mhlw.go.jp/stf/covid-19/open-data.html)を使おうとすると、”陽性者数pcr_positive_daily.csv”と”入院治療を要する者の数”cases_total.csvのどちらを使うべきか迷う事になる。Rtは1st case→2nd caseの倍率なので、必要なのはcases_dailyであるはずだ。しかし、ここでcases_total.csvからdailyを作ろうとすると、マイナスの値が続々発生して、、どうも定義が違うらしいorzということで断念して、”陽性者数pcr_positive_daily.csv”を使ってみた。
(6) Estimate R!

(7) Figuresタブが開いて、Incidence、Serial interval distribution、R averaged over time periods (posterior median and 95%CrI)の3つのグラフが表示される。

Rの計算の最初の方は少々おかしいが、まぁご愛敬ということで。
日本の2020/3/1~2020/9/25の結果

論文についているPythonやらRやらのプログラムを動かそうとして、インストールだのバージョン問題だのに振り回されて毎度1ヶ月以上要していた事を考えると、Excelは神
ただし、中はいじるなとのことで、自分の研究の参考にするのはちょっと難しそうかな。
【参考文献】
WHO(2020) Public health criteria to adjust public health and social measures in the context of COVID-19
Anne Cori(2013) A New Framework and Software to Estimate Time-Varying Reproduction Numbers During Epidemics
キーワード 実効再生産数
【新型コロナ】何も対策しない場合の死者数がなんと!?
前回の反省から、ちゃんと修正しようと思っていろいろ調べておりましたが
思いの外はまってしまい、このままでは飽きてしまって風化させる恐れがあるので
これまで分かったところだけでも書こうと思います。
「何もしなければ41万人死亡」というのは4月に北大の西浦氏が発表された内容で、ショッキングだったので噂になりましたが、少し前の事なのでもしかするとご本人も何かアップデートされているかも知れません。
私は疫学については専門家ではないので、、とお断りした上で、
WHOの3/4付けのCOVID-19とインフルエンザの比較記事のデータを元に、
基本的な疫学モデルであるSIRモデル(1930年頃に発表されその後も脈々とマイナーチェンジされている)に入れて、エクセルで計算しました。
SIRモデルは、S(感染していない)、I(感染者)、R(回復、もしくは死亡)という群を想定しています。
絵にするとこんな感じです。一度感染して回復した人は、免疫がついて再度感染しないという事がミソになっています。

ここで、WHOの基本再生産数R0は、感染する強さを表し、発症間隔(SI)は、感染を次に引き継ぐ時間を表します。

そして、パラメータを入れてSIRモデルでS、I、Rをプロットするとこんな感じ。


ここで、Rというのは一度感染した人の累積になり、最終的に94%が感染する結果になっています。
一昨日の厚生労働省のデータから、感染者に対する死亡率は約5.7%と計算できる(この値がそこそこ変動する点に注意が必要)ので、
人口1億2千万の94%の5.7%といえば、死者数670万人という事になる、、えっっ何か間違ってない?これ!??
まぁそんなとこで。。^^;
ピークもCOVID-19はインフルエンザの2.5倍なので医療崩壊必至な様子です。
ところで、実際のインフルエンザの感染がこの結果と同じかというとそうではありません。インフルエンザでは、ワクチンが投与されているからです。しかし、ワクチンは、インフルエンザを流行させないように投与されているはずなのにも関わらず毎年1000万人も感染しているっておかしくないですか?
そう、単純なSIRモデルでは、インフルエンザの感染者数は計算できません。ここまでのSIRモデルは平均値で話をしていますが、値にはばらつきがあるので、幅を持っている。だから、なんちゃら分布にフィッティングという話が始まるんでしょう。
、、にしても、1000万人って多くない?
そう、この1000万人が、しかも、毎年推定1000万人とか言っており、生データが拾えなかった、、orz
↑それではまっていたんですね。(TT)
ほとんどの人が保険診療なのだから生データがありそうなものだけれど、保険データは見つからず、都道府県別データは、定点観測とかいう昭和初期から続いているようなデータで、、
インフルエンザのデータは都道府県別だけど、インフルエンザの種類別データは都道府県別ではないとか(そもそも、SIRモデルは単一の病原体でなければ想定がおかしいでしょう)、、国立感染症研究所はデータの提供方法がスマートでありがたかったのですが、、内容が結果的に使えなくて残念だった。それとも私の探し方が悪かったのか。
もしかして、これもあれかしら?
日教組と文部科学省が仲が悪いように、厚生労働省と保険機構も仲が悪いのかしら?
と、余計なことを考える今日この頃。
新型コロナ対策を考えるにあたって、インフルエンザの都道府県別生データがあれば参考になるかと思います。定点観測データは、専門家の方には有用なデータなのかと思いますが、独特な値なので、おそらく海外で通用しないのではないかと思いました。
最後に、謝辞
多くのCOVID-19関連の論文や周辺論文が広く無料でアクセスできる状態で提供されており、本当に、人類一丸となってコロナと戦おうとしているのだと、感動しました。
関係者の皆様方、本当にありがとうございます。